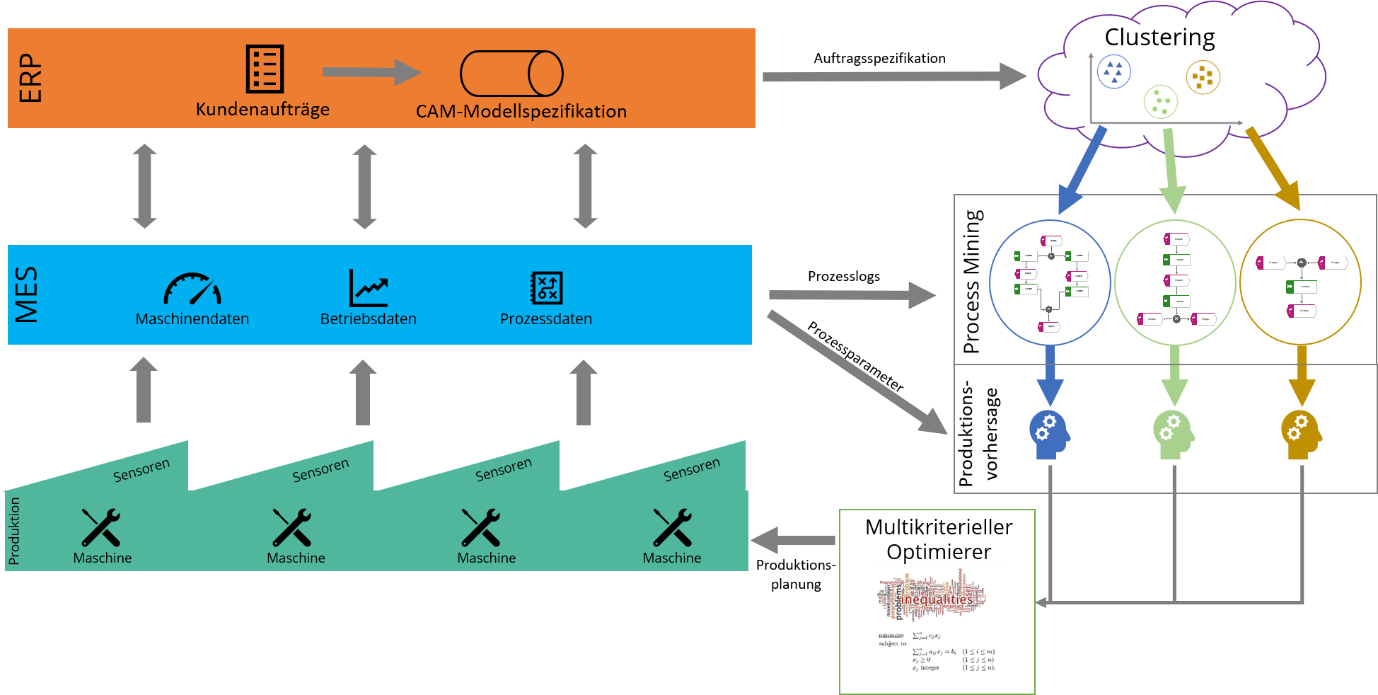
Nach ausführlicher Analyse der Prozessinformationen ist es nun möglich, Predictive-Analytics-Modelle anzuwenden um die Unsicherheit der Produktionsprozessparameter (wie beispielsweise Rüstzeiten, Liegezeiten, Energieverbrauche, Qualitätsschwankungen, unerwartete Kosten usw.) zu quantifizieren. Dabei können abhängig von der Vielschichtigkeit der Ziele neben den einfachen Algorithmen des maschinellen Lernens, auch komplexe Algorithmen wie beispielsweise Ensembles der konventionellen ML-Algorithmen angewendet werden. Neueste vielversprechende Anwendungen von Deep-Learning-Algorithmen, sowohl für Regressions- als auch Klassifikationsprobleme, zeigen große Potenziale zur Prozessanalyse.
In unserem Projekt werden wir den branchenübergreifenden Standardprozess für Data Mining (Cross Industry Standard Process for Data Mining CRISP-DM) um die entsprechenden Vorhersageanalysen durchzuführen. Die CRISP-DM Methode umfasst sechs Hauptphasen. Es ist kein linearer Prozess; die Phasen stellen vielmehr einen laufenden Zyklus aus Aktion und Analyse dar und es gibt oft Vor- und Rückschritte innerhalb und zwischen den Phasen. Abbildung 2 gibt einen Überblick über die einzelnen Schritte.
Die Überlegenheit Neuronaler Netze bzw. Deep-Learning-Modellen gegenüber konventioneller Prognoseverfahren in verschiedenen Anwendungsbereichen ist Gegenstand umfangreicher Literatur. Diese s.g. „Black-Box Modelle“ haben jedoch die Einschränkung, den menschlichen Experten keine nachvollziehbaren Erklärungen über das Zustandekommen ihrer Entscheidungen und Handlungen zu liefern. Die unzureichende Nachvollziehbarkeit des Entscheidungsprozesses wird mithin als einer der Hauptgründe gesehen, warum der Fortschritt in der ML-Forschung immer noch so geringe Akzeptanz in der Geschäftswelt genießt. Obwohl die datengetriebenen Analysemodelle durch Black-Box ML-Modelle in der Regel bessere Vorhersagen liefern machen erstens die Fähigkeit unstrukturierter Informationen besser zu verarbeiten und zweitens operative Prozessintelligenz auf Basis von Erfahrungen die Anpassungen durch Domänenexperten unerlässlich. Um die Kombination aus Expertenkenntnisse und datengetriebenen Analysen effektiv zu gestalten, sollen die ML-Algorithmen transparent, verständlich und nachvollziehbar sein.
Datengetriebene Analyse/Vorhersage der Prozessparameter zur Produktionsplanung bei Einzelfertigern zielt darauf ab, die Unterstützung von Entscheidungsprozessen voranzutreiben, welche Überzeugungs-, Intuitions-, Urteils- und Anpassungsfähigkeiten erfordern. Die Operationalisierung solcher intelligenter ML-basierter Systeme durch Einbettung in die Geschäftsprozesse erfordert jedoch einen Übergangsprozess, in dem das Vertrauen in die Aktionen, Inferenzmechanismen und Ergebnisse des Systems aufgebaut werden muss, da ihre Akzeptanz ohne Vertrauen erheblich eingeschränkt ist. Die Erklärbarkeit wird als Mittel betrachtet, um das Vertrauen der Nutzer in das Modell zu erhöhen. Die Interpretierbarkeit bzw. Erklärbarkeit der Machine Learning Modelle ist jedoch kein monolithischer Begriff und bezieht sich auf mehrere Dimensionen zweier Kategorien:
(i) Modelltransparenz auf globaler Ebene und
(ii) post-hoc Erklärung der Modelle.
Im Rahmen des MES4SME Forschungsvorhabens werden unterschiedliche Dimensionen dieser Problemstellung systematisch adressiert und erfolgreiche Ansätze übernommen und weiterentwickelt.